一、AMQP协议
简介
AMQP是一种高级消息队列的二进制协议,提供了统一的消息服务标准,是应用层协议的一种标准,为面向消息的中间件设计。
就是说,AMQP只是一种协议或是规范,它其中有着很多关于消息的概念,比如当我想开发一个消息中间件,PaceMQ时,就可以根据这些概念走。
协议模型
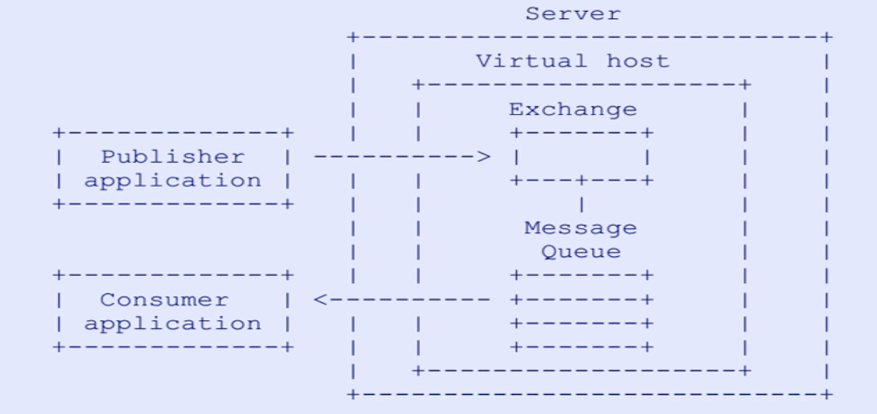
消息队列(Messages Queue),从字面意思是,本质是一个队列,先进先出规则,只不过队列中存放的是messages消息而已。
主要用途是不同进程/线程间通信,比如服务A调用服务B就可以通过MQ。
有几个原因:
ES对于其他的一些应用来说,能够优化的地方非常少,其实最大的优化就是给予它足够大的内存,我们说下其他一些优化。
ES会自动开启慢查询日志,来查看插入搜索哪些性能比较慢,然后再考虑如何优化写入或搜索的性能。
在elasticsearch.yml中配置快慢的阈值,即多少秒算慢,需要写到日志里
1 | index.search.slowlog.threshold.query.warn: 10s |
对于慢查询日志的日志格式,是在log4j2.properties中配置,es默认会给出一些配置,可以根据自己的需要修改。
当我们想要搭建集群时,要先了解下ES的集群发现机制zen discovery
在默认情况下,es进程会绑定在自己的回环地址上,会去寻找9300-9305端口是否有es node,如果有并且启动,会主动与其通信,组成集群。这样的话如果本地启动多个节点,其搭建集群是非常方便的。但是生产环境不是这样,因为是在不同服务器上进行集群的搭建,需要绑定到非回环的ip地址上,并使用集群发现机制进行通信。
集群发现机制常用的有两种:
我们开始学习搭建集群,这里搭建4节点的虚拟机集群,每个虚拟机1核2G,因为我笔记本只有16G,需要留8G。
软件:VMware10,centos7
这里正常安装即可,主要配置下内存为2G,名称为elasticsearch01即可
安装完毕需要配置网络,因为是centos7与之前的6.x不同,6.x的百度一下
vi /etc/sysconfig/network-scripts/ifcfg-ene33,然后按照如下配置,其IPADDR和GATEWAY的前三位可以根据自己虚拟机默认配置的配,使用ip addr查看
本章主要介绍生产环境中ES集群其硬件配置需求,需要根据我们的需求来决定部署的机器的内存,cpu,磁盘,jvm等等的资源配置。这里简单介绍一下
ES对于内存来说,占用量很大,他不仅是占用JVM的内存,还有机器的内存。
因为ES底层是Lucene,Lucene是基于磁盘文件来读写索引数据的,倒排索引正排索引,Lucene会大量使用 os cache,频繁访问磁盘数据再内存中进行缓存,所以如果内存大,其性能便会高,因为os cache能缓存更多的数据,而不用去对磁盘进行操作,磁盘操作减少性能便提高。
如果生成环境中,es上千万数据搜索需要10s来完成,那么大概率是内存不够用了,需要分配更多的内存才行,进行了大量的磁盘读写操作。
关于内存相关知识,这里只是简单介绍一下,后面再细说。
ES是一个分布式系统,为了对应大数据量,ES对于复杂的分布式机制隐藏了很多特性
ElasticSearch简称es,是基于Lucene的一款分布式全文检索服务器,实时存储,检索数据,分布式处理PB级别数据,自动分片并维护冗余副本,数据安全,扩展性好是它的几大特点。es也使用Java开发,底层为Lucene来实现索引搜索功能,但是它使用RESTful风格API来简化Lucene复杂的操作,从而使得全文检索更简单。
所有用到搜索的地方都有ES的影子,如:
github的搜索功能,github自2013年起使用ES来作为搜索引擎,来处理PB级别的数据。
维基百科:启动以elasticsearch为基础的核心搜索架构
SoundCloud:“SoundCloud使用ElasticSearch为1.8亿用户提供即时而精准的音乐搜索服务”
百度:百度目前广泛使用ElasticSearch作为文本数据分析,采集百度所有服务器上的各类指标数据及用户自
定义数据,通过对各种数据进行多维分析展示,辅助定位分析实例异常或业务层面异常。目前覆盖百度内部
20多个业务线(包括casio、云分析、网盟、预测、文库、直达号、钱包、风控等),单集群最大100台机
器,200个ES节点,每天导入30TB+数据
新浪使用ES 分析处理32亿条实时日志
阿里使用ES 构建挖财自己的日志采集和分析体系