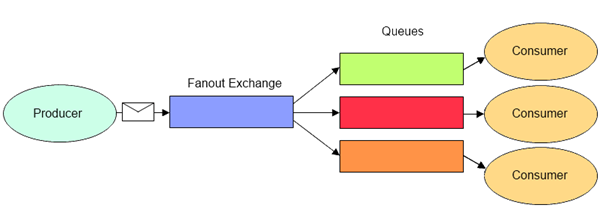
Spring AMQP是用于以AMQP为基础的MQ中间件的解决方案,对于底层API进行封装,使开发者在对MQ进行操作时更加易用,并进行了一些拓展与优化。
这里我们主要使用RabbitMQ与SpringAMQP整合,对于其他以AMQP规范制作的中间件也是差不多的整合方式。
SpringAMQP核心内容
RabbitAdmin:管控组件RabbitTemplate:消息模板组件SimpleMessageListenerContainer:简单消息监听容器MessageListenerAdapter:消息适配器MessageConverter:消息转换器
接下来,我们就需要对这些核心内容进行研究
RabbitAdmin
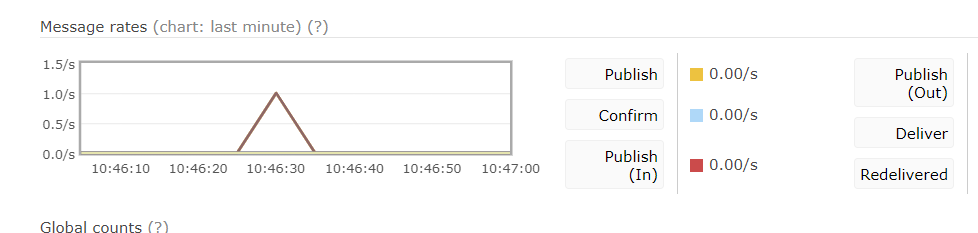
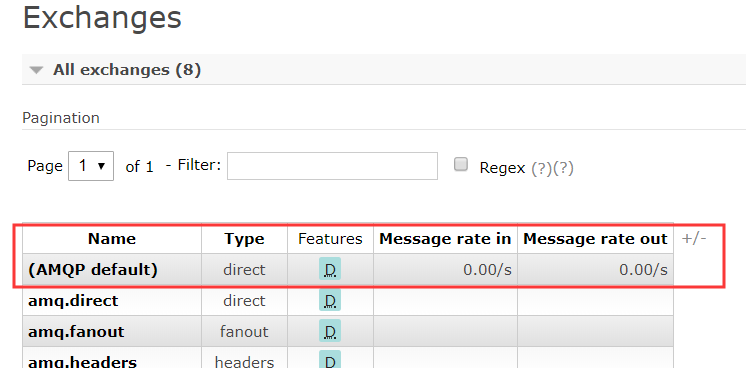
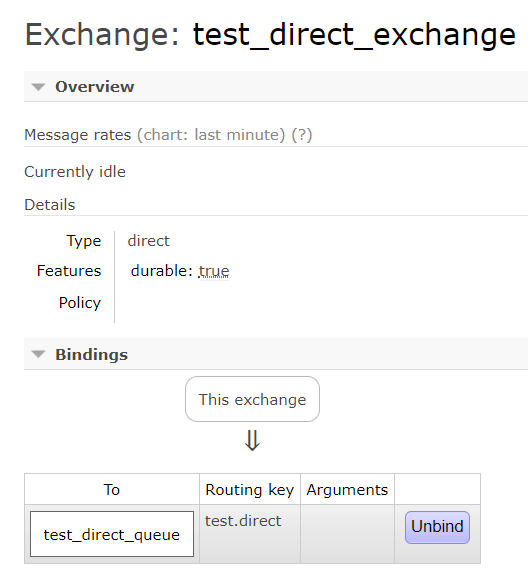
RabbitAdmin的主要作用就是方便的操作Exchange,Queue,Binding这些信息
使用它需要几点注意:
- 需要将
RabbitAdmin注入到上下文中,注入的前提是ConnectionFactory在上下文中,所以要先注入ConnectionFactory - 注入时要设置
autoStartup=true,不然不会加载RabbitAdmin