本笔记分析研究对于ES的search功能的原理
一、查询分页
通过之前的学习,我们可以知道搜索时可以通过from和size字段来配置分页信息
1 | POST /ecommerce/product/_search |
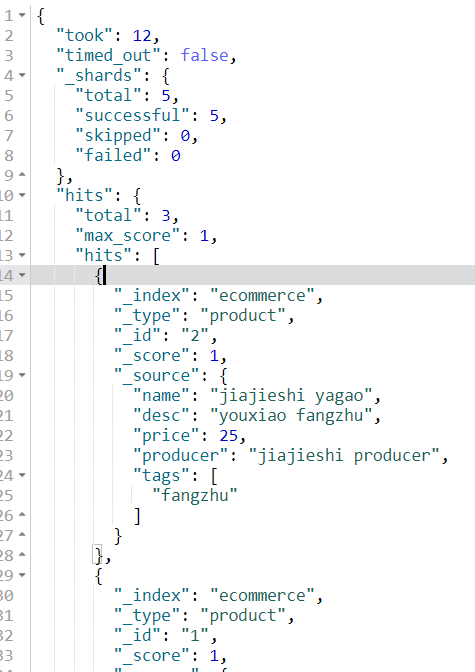
我们先进行结果分析,
- took:查询使用12毫秒
- timed_out:没有超时
- _shards:查询请求了多少个分片,成功请求多少个分片
- hits:命中数量,最大匹配分数,具体命中数据
当我们看数据时,发现_id为2的在前,_id为1的在后,这是es底层分页导致的。
es查询分页原理:举例3个shard,3000条数据,查询from=100,size=10
- 因为from100,size10,即需要100-109的数据
- es协调节点向3个shard发出请求,要求获取每个shard的0-109的数据,注意是0-109
- 每个shard接收到请求后,会创建一个
from+size大小的priority queue,一个优先队列,将查询出的数据放入队列再全部返回给协调节点。 - 协调节点获取到这些数据,总数据量为330条,将这些数据放到自己的
priority queue,然后对这些数据进行排序 - 排序后将序号为100-109的数据返回给客户端
这时我们会发现,如果数据量增加到30万条,而用户需要最后10条,那么es的协调节点需要临时存储30万条数据且进行排序,会导致大量资源耗费,所以对于ES的分页,要尽量避免DEEP PAGING的情况。
二、全域搜索
ES提供了一种query string的字段,可以将关键词分词再进行搜索,并且可以全域搜索,即不指定查询哪个field
1 | POST /ecommerce/product/_search |
问题提出:不指定field,ES底层是如何处理并查询所有域呢?难道是对每个field都进行查询吗?
如果对每个field都进行一次查询,太繁琐且性能低,ES的底层不是这样的,它有一个元数据_all field,在建立索引保存document的时候,会讲所有域的值串成一个字符串并赋值给元数据_all field。
例如:
1 | { |
当全域搜索的时候只需搜索_all field元数据即可
三、mapping
我们之前了解mapping就类似一张表的数据结构,定义了多个字段,我们回过头来再研究一下
1)在es里直接插入数据时PUT shop/book/1及数据信息时,es会自动建立索引、type和mapping
2)mapping会根据数据自动定义field的数据类型,如2018-01-01日期格式的数据类型为date,100数字格式的为long
3)不同的数据类型可能有的是exact value精准匹配,有的是full text全文检索。比如text就为全文检索,date就为精准匹配
4)exact value在建立倒排索引时,是整个词进行建立,full text是使用分词器分词后再对不同的词进行建立。所以在搜索时也不同
5)mapping的建立可以让es自动建,或者手动设置mapping的field,包括数据类型,分词器,是否存储,是否索引等等
这里我们举个例子来看一看精准匹配与全文检索

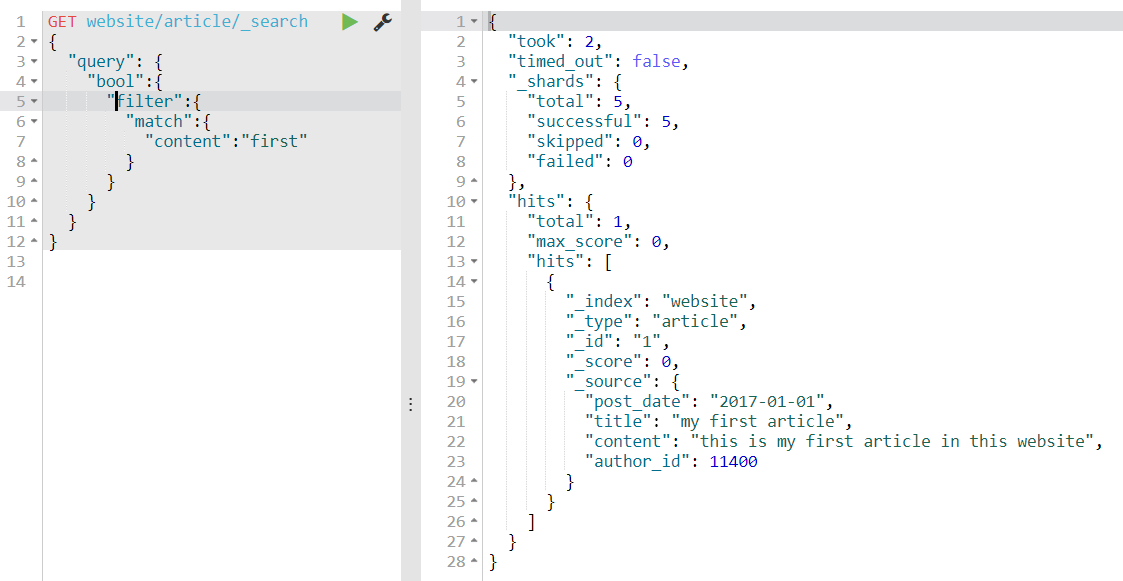
创建两条数据,website/article,因为是直接插入的,所以mapping是es自动创建的,我们看下mapping格式
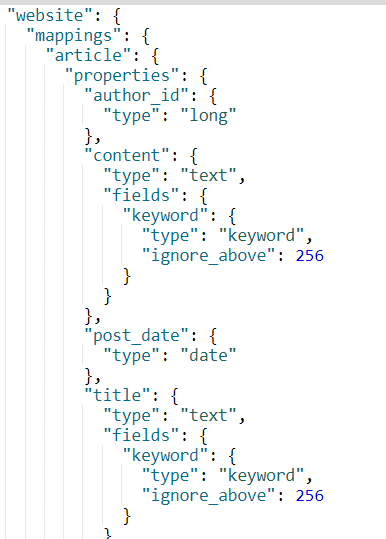
可以看到author_id是long,post_date是date,和我们上面说的一样。
我们通过上面说的全域搜索query string进行查询一下试一试:
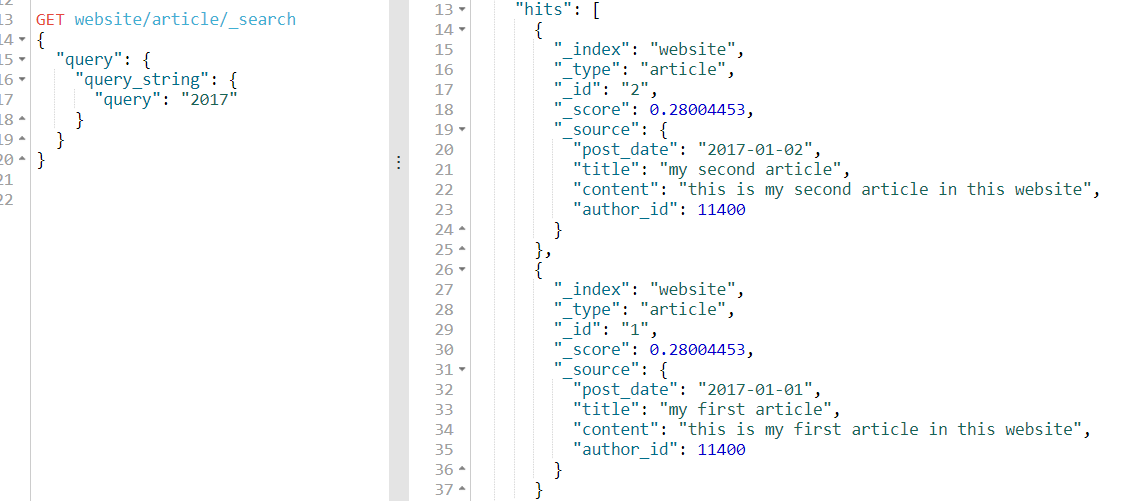
可以看到我们全域搜索2017可以查询出2条数据
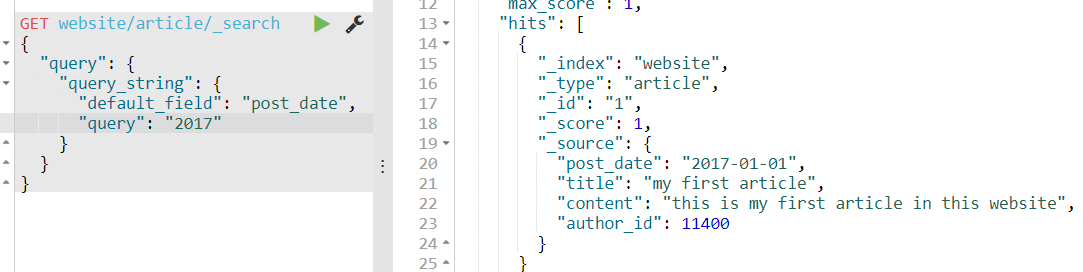
如果我们指定域post_date查询,只能查到一条,为什么呢?
全域搜索:查询的是_all field的字段,其类型text属于全文检索,即对2017-01-01这个数据分词后再查询,所以有2条
指定域:查询的是post_date字段,其类型date属于精准搜索,即对日期没有分词,又因为es5.x之后的优化,所以能查出一条记录,其实在5.x之前的版本是一条都查不出来的。即只能用2017-01-01这个搜索关键词才能查出。
四、Filter和Query
在前面已经学习了如何过滤数据。
这样一看,发现filter和query的功能好像差不多,能相互转化,那么到底应该用什么呢?
query:每次查询需要进行计算匹配值并排序,无法缓存结果
filter:每次只按搜索条件过滤,不排序计算,会缓存结果
这样一看,使用场景显而易见了,这里要说下,看着filter不计算,效率肯定比query高,其实不然,在第一次查询时,query的效率可能还会比filter高,因为filter需要缓存结果,但是除了第一次查询,filter的速度比query快几十上百倍。
五、ES的相关度评分
在进行查询操作时,前面介绍说排序默认是按_score分数来排的,且es底层的计算排序也是如此,那么到底是如何排序计算呢?就是我们要讲的相关度评分,TF/IDF(词频/逆向文档频率)
官方文档告诉我们,分数的由来主要有三个因素决定
5.1.词频(TF)
词频即词在文档中出现的频率,频率越高,权重越高,计算公式为:
$$
tf(td) = √frequency
$$
词t在文档d的频率是:该词在文档中出现次数的平方根
例如:搜索hello world
doc1:hello you, and world is very good
doc2:hello, how are you
那么分词后在doc1出现2次,doc2出现1次,即doc1分数高
如果不在意词在某个字段中出现的频次,而只在意是否出现过,则可以在字段映射中禁用词频统计:
1 | PUT /my_index |
设置其field的index_options为docs,即计算分数时不会再计算词频TF
5.2.逆向文档频率(IDF)
即词在总文档中出现的频率,频率越高,分数越低
$$
idf(t) = 1 + log ( numDocs / (docFreq + 1))
$$
词 t 的逆向文档频率( idf )是:索引中文档数量除以所有包含该词的文档数,然后求其对数。
例如:搜索hello world
doc1:world is very good,bro(world在总document中出现1000次)
doc2:hello, how are you(hello在总)
因为doc1的出现次数更多,所以doc2的分数更高
5.3.字段长度归一值(flnorm)
Field-length norm:字段的长度越长,其分数越低
$$
norm(d) = 1 / √numTerms
$$
字段长度归一值( norm )是字段中词数平方根的倒数
例如:搜索hello world
doc1:world is very good,bro
doc2:hello, how are you
因为doc2的长度更短,所以doc2的分数更高
Norm和TF一样也可以禁用的
1 | PUT /my_index |
设置其field的norms为false,即计算分数时不会再计算Norm
六、SearchType
ES是分布式的全文检索系统,其特点就是分片存储数据,ES如何获取用户需要的数据且排序呢?ES搜索排序分为两步:
1)ES向5个分片发出请求,叫Scatter
2)5个分片独立搜索,将符合条件的数据返回,ES将数据集中起来再进行重新排序,返回给用户,即Gather
这样就会出现问题:
1)数量问题:用户需要10条数据,ES向5个分片发出前10条数据的请求,得到结果会有50条数据,ES再进行排序返回,用户就会获得50条数据,不符合请求数量。
2)排序问题:ES的排序是基于分片传来的分数的,即每个分片有不同的使用频率,举个例子:分片1的name字段的mike使用200次,allie使用100次,用户查询1条最高使用数据,当然分片1返回mike,这时分片2的name字段bob使用10次,jasper使用5次,就会返回bob,这样的话明显allie的使用频率更高。所以如果要解决这种情况,ES要先获取分片上频率,然后统一计算后再排序查询。
这两个问题,估计ES也没有什么较好的解决方法,最终把选择的权利交给用户,方法就是在搜索的时候指定query type。
有三种SearchType:
- Query and fetch:即ES请求所有分片,返回n*5的数据整合排序,就会出现上面的问题,返回数量是用户要求的n倍。这种方法以及被弃用了
- query then fetch:ES请求所有分片,获取排名相关的信息,而不是数据,es获取后进行计算然后再根据计算结果向不同分片请求数据,这样可以解决上面数量问题和排序问题。默认使用,也最常用
- DFS query then fetch:同样多了初始化散发过程。
七、零停机重建索引
前提条件:Java应用中使用的别名查询而不是索引名
经过之前的学习知道field属性一旦创建就不能被修改,比如创建时是text,你不能后面再修改成date类型,那么我们模拟一下真实生产场景:
7.1.问题的提出
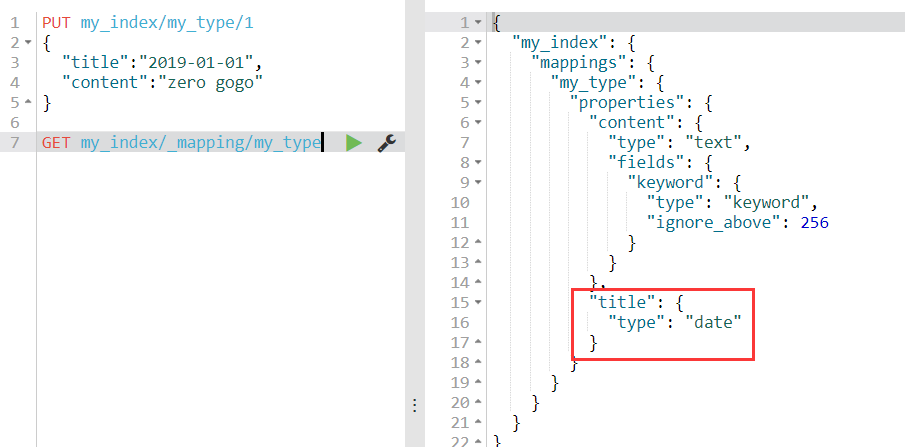
1)创建document,使用dynamic mapping,但是不小心把title的类型设置成date了,实际是text类型
1 | PUT my_index/my_type/1 |
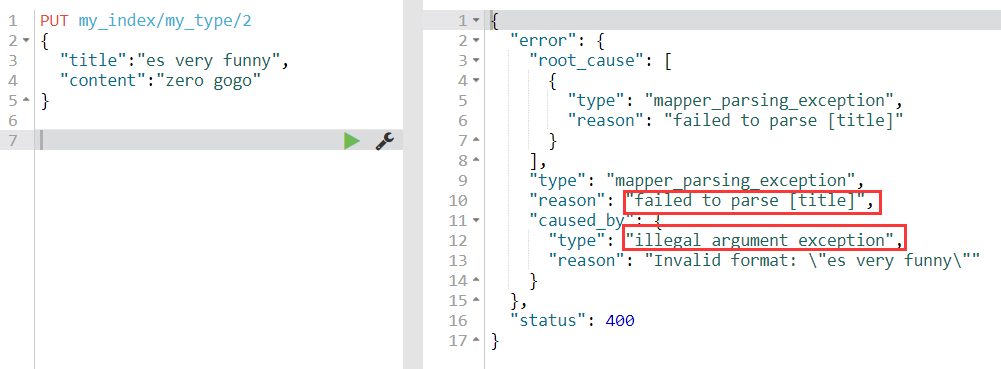
2)向索引添加text类型的title数据,因为类型不匹配报错
3)因为不能直接修改,所以需要重建索引
7.2.问题的解决
1)创建索引,配置正确的field类型
1 | PUT /new_index |
2)设置别名,将新索引加入到旧索引的别名上(Java程序使用的是别名)
1 | POST /_aliases |
3)使用reindex api同步索引数据
1 | POST _reindex |
4)查看新索引数据是否同步成功
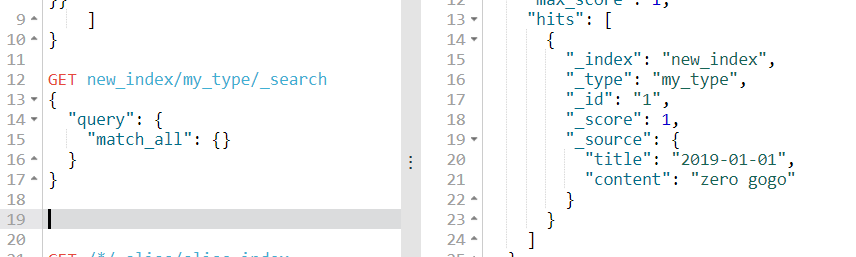
同步成功
5)删除别名中的旧索引
1 | POST /_aliases |
八、深入document读写机制底层
在前面讲document如何写入时,是说协调节点分配通过路由计算分配给不同的节点进行写入,今天我们来讲讲具体节点中primary shard是如何把document写入到磁盘中的。
8.1.写入原理
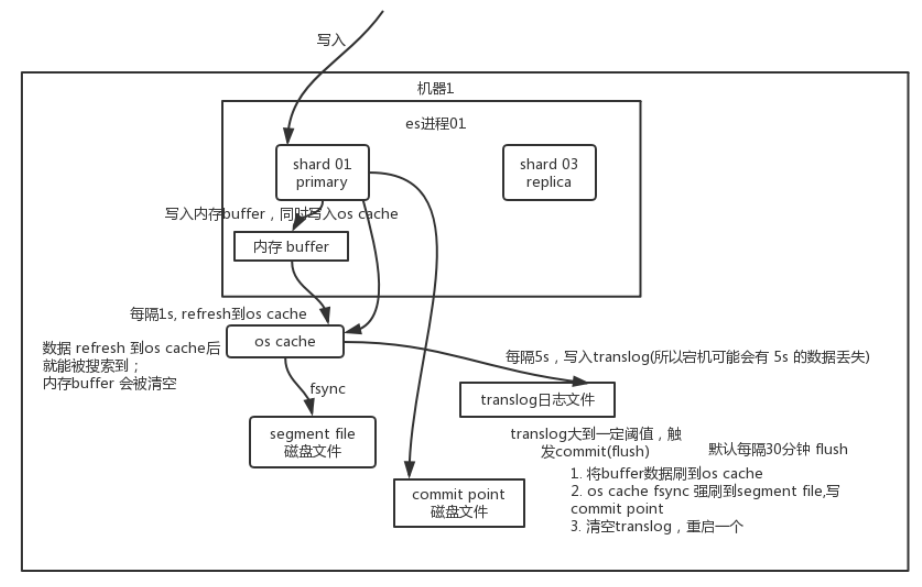
1)shard将数据先写到内存buffer中,在内存中的数据是搜索不到的
2)buffer每隔一秒将数据刷到file上,即segment file,但是如果这时直接将file写入磁盘,效率会非常慢,而且用户就无法NRT近实时搜索数据,所以会先将segment file数据刷到os cache中,即系统缓存
3)buffer数据进入os cache中后,buffer清空,数据可以被搜索到
4)buffer清空了,数据存在os cache,宕机不就全部丢失了?这时就出现了translog日志文件,数据进入shard后,不止将其写入到buffer中,还将一份写入到translog中,当然也是先保存在translog的cache中,然后每隔5s会将translog cache中的数据写入到translog中,即保存到磁盘上(所以这5s如果宕机,可能会丢失5s的数据)
5)重复上面的操作,buffer每隔一秒写入到新的segment file中,然后写入os cache中,并每隔5秒刷数据到translog中
6)当translog越来越大,会进行一次commit(flush)操作,默认30分钟flush一次
6.1)将buffer所有数据保存到新的segment file,然后刷到os cache中
6.2)将一个commit point写入到磁盘,这个commit point保存了对应所有的segment file
6.3)将os cache中的所有index segment file缓存数据,被fsync强行刷到磁盘上
6.4)清空translog,创建一个新的translog,commit结束
实际上你在这里,如果面试官没有问你 es 丢数据的问题,你可以在这里给面试官炫一把,你说,其实 es 第一是准实时的,数据写入 1 秒后可以搜索到;可能会丢失数据的。有 5 秒的数据,停留在 buffer、translog os cache、segment file os cache 中,而不在磁盘上,此时如果宕机,会导致 5 秒的数据丢失。
8.2.更新/删除原理
当数据写入buffer后,并刷入os cache,这时会有一个commit point操作,标志这些数据是属于哪个segment file的,这时就会生成一个.del文件,将里面某个docment标为deleted状态,这样搜索时便会过滤掉。
8.3.再次优化
我们知道,每过一秒写入一个新的segment file,那么segment file会非常庞大,所以一段时间后,es会自动进行merge操作,将一些segment合并,并且会将标记为deleted数据物理删除
merge执行流程
1)选择大小相近的一些segment file,merge成一个大的segment
2)将新的segment file刷到os cache中
3)写一个新的commit point,包括新的segment以及排除旧的segment
4)将新的segment打开提供搜索,删除旧的segment