ES对于Java客户端提供了两种连接方式
- Transport连接:基于TCP的连接方式,即使用9300端口,即执行Java请求
- REST client:高级客户端,使用REST请求,基于9200端口,执行Http请求
对于ES来说 es8以上便没有transport客户端了,即弃用,所以更推荐使用High level rest client,简称高级客户端。
对于学习阶段,准备将两种方式都简单学习一下。
一、Transport客户端
Java对ES进行操作,首先需要一个客户端。
1.1.获取TransportClient
客户端的创建:1.设置settings,配置集群名称 2.获取client,配置节点端口与IP
1 | private TransportClient client; |
1.2.创建索引
1 |
|
因为上面已经在把client当做成员变量了,所以不再初始化。
1.3.设置mappings
1 |
|
在post中,我们以json形式填入请求体,再java执行请求也一样需要拼接请求体,可以使用json字符串或es官方的XContentBuilder对象,这里我们使用XContentBuilder,创建Document时使用Json字符串。
1.4.创建Document
1 |
|
这里Json串是直接拼接的,当然,也可以使用Bean转Json插件,先创建个Entity实体,再进行转换json字符串。
1.5.查询功能
查询有三种,根据id查询,根据Term查询与根据QueryString分词查询
这三种查询都依赖QueryBuilder对象,差别也仅仅在QueryBuilder对象的构建上。
1 |
|
1.6.查询分页与高亮
对于分页与高亮都是在client查询时进行添加参数
分页:执行查询时设置From(从第几个数据开始),Size(一页多少个数据)
1 | client.prepareSearch("java_index").setTypes("book").setQuery(queryBuilder) |
高亮:需要先设置HighlightBuilder对象,field(在哪个域高亮),preTags(关键字前添加),postTags(关键字后添加)
1 | // 高亮显示查出结果 |
对于高亮结果的获取如代码所示。
二、High Level Rest客户端
2.1.客户端初始化
高级客户端的创建内部需要创建低级客户端来提供builder,低级客户端会维护一些线程,所以关闭时需要close释放线程。
对比TransportClient,高级客户端的创建简单了很多,如下:
1 |
|
这里getRequest即根据ID查询索引信息
2.2.新增索引
1 |
|
可以看到,高级客户端明显比Transport客户端操作清晰明了,对于不同操作具有不同的Request
2.3.设置mappings
1 |
|
2.4.增加修改Document
1 |
|
2.5.删除索引
1 |
|
2.6.删除Document
1 |
|
2.7.根据ID查询
这里分为单个ID查询和批量ID查询,如下:
1 |
|
即一个为GetRequest,一个为MultiGetRequest
2.8.根据Term查询
根据Term查询会发现查询方式改变了,这也是es最常用的查询方式
即:
1.创建一个SearchRequest,设定请求信息,如:索引名,Type类型,SearchType类型。
2.创建SearchSourceBuilder,配置查询信息,如:分页情况,如何查询(Term查询,聚合查询等),高亮显示,超时时间
3.使用QueryBuilders配置查询方式,这里方式比较多,下面介绍
这里searchType类型下面介绍。
1 |
|
2.7.1.QueryBuilders类型
1 | // 设置QueryBuilders查询方式 |
可以看到常见的有这几种,还有一种比较重要的是复合查询:
1 | BoolQueryBuilder boolQuery = QueryBuilders.boolQuery(); |
这段符合查询意思是,查询content中含有content且title中不含有document的数据


可以看到正确显示出id为3的数据。
2.9.聚合查询
聚合查询使用AggregationBuilders来创建聚合条件
一般来说使用方法:
1 | // 聚合查询,terms为聚合后字段名,field为字段名 |
我们想进行获取每个学生总成绩,便需要聚合查询:
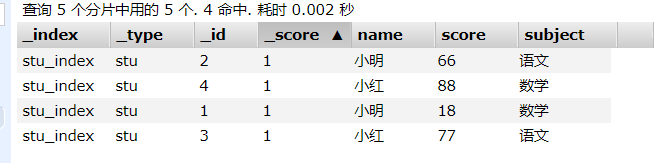
代码:
1 |
|
执行后会发现报错:

这是因为我们的name字段时text属性,而ES5之后对text属性聚合需要花费大量时间,默认是禁止的,这时我们需要重新设置name属性:
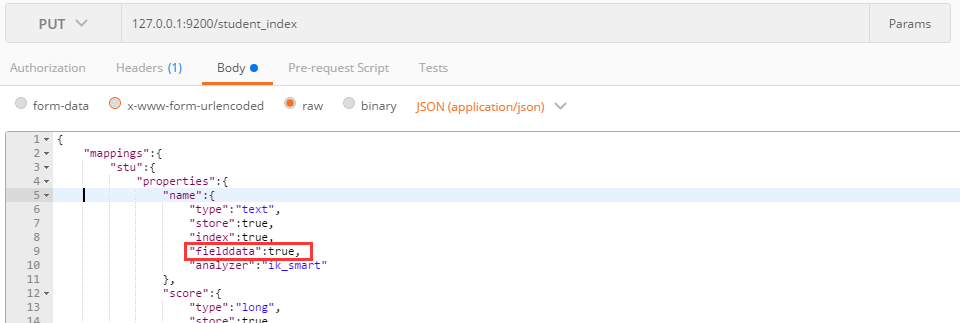
设置fielddata为true。
再次执行,发现又报错!

上网查没有查到结果,思考一下,我这java是6.6的api,而es引擎是5.6的,是不是版本冲突问题呢,我下载一个6.x的ES启动后再次执行,可以获得想要的结果。